
Tesslate • Research Preview




WEBGEN-4B-Preview
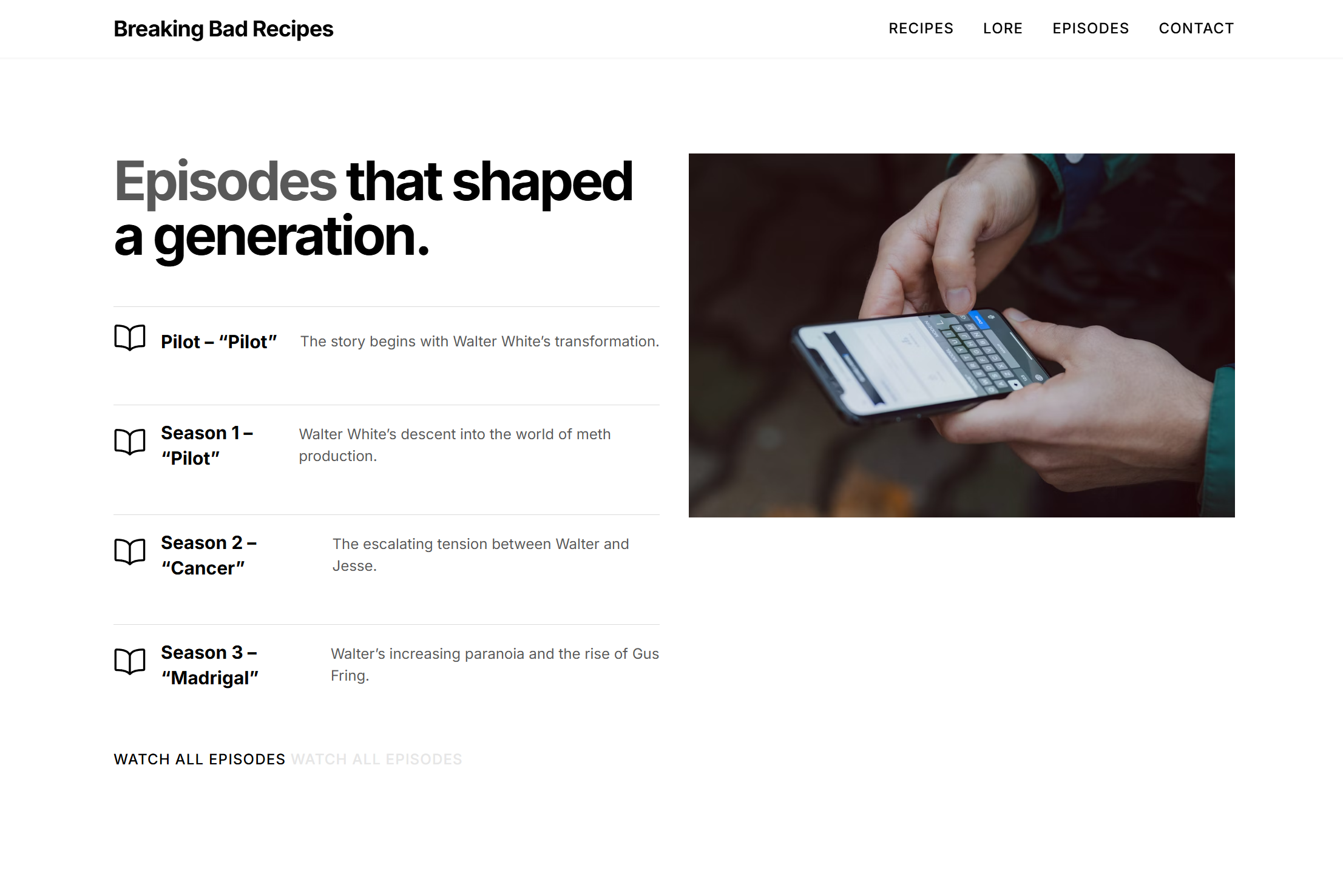
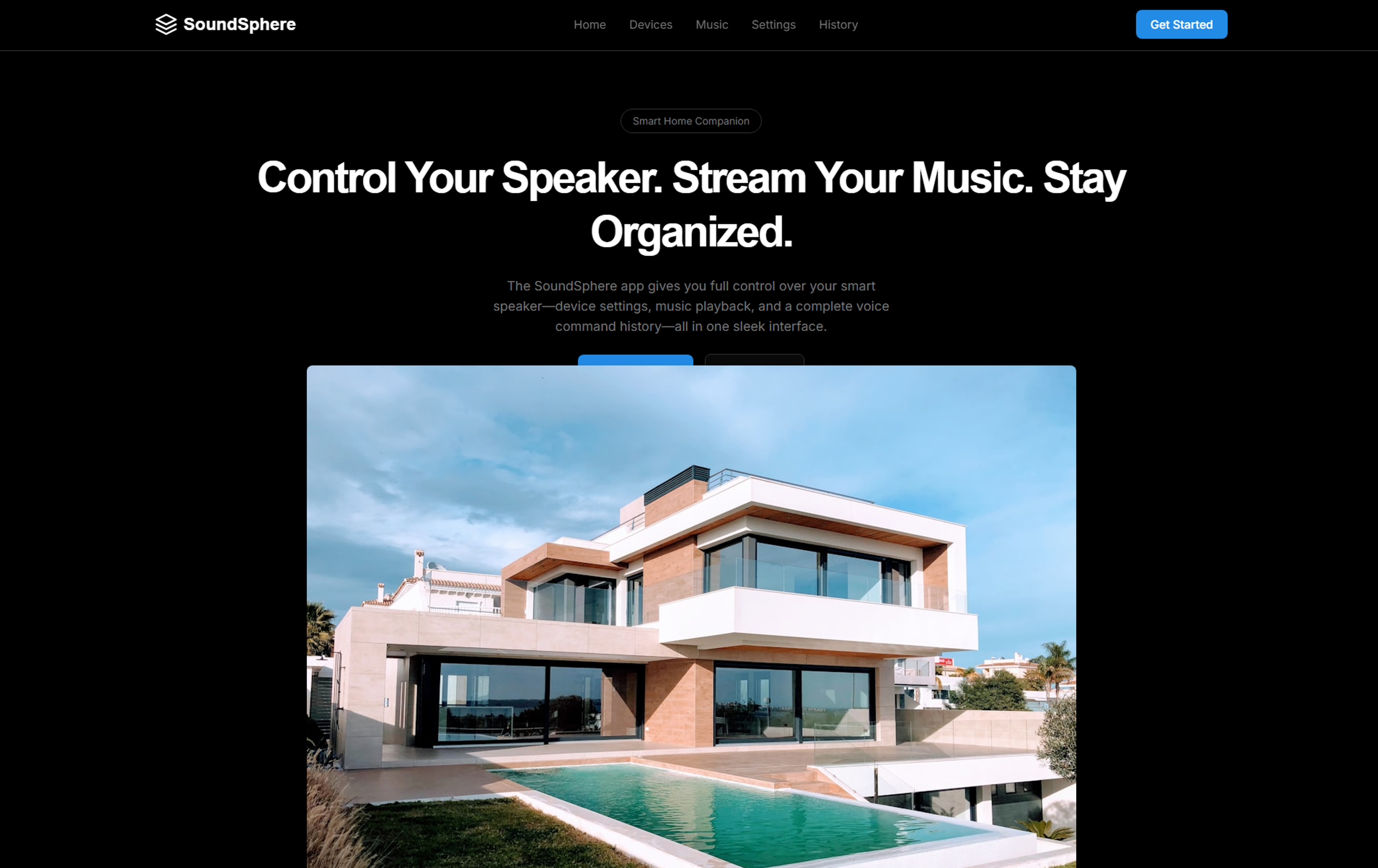
A 4B web-only generator that turns one prompt into clean, responsive HTML/CSS/Tailwind. Small enough for laptops; opinionated for consistent, modern layouts.
Open weights
Web-only bias
Mobile-first output
No external JS by default
What it is
WEBGEN-4B-Preview focuses solely on generating production-lean websites. It prefers semantic HTML, sane spacing, and modern component blocks (hero, grids, pricing, FAQ).
Why 4B
Small enough for local runs and fast iteration, while retaining strong structure/consistency for HTML/CSS/Tailwind output.
## Quickstart ### Transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "Tesslate/WEBGEN-4B-Preview"
tok = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = """Make a single-file landing page for 'LatticeDB'.
Style: modern, generous whitespace, Tailwind, rounded-xl, soft gradients.
Sections: navbar, hero (headline + 2 CTAs), features grid, pricing (3 tiers),
FAQ accordion, footer. Constraints: semantic HTML, no external JS."""
inputs = tok(prompt, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=2000, temperature=0.7, top_p=0.9)
print(tok.decode(out[0], skip_special_tokens=True))
vllm serve Tesslate/WEBGEN-4B-Preview \ --host 0.0.0.0 --port 8000 \ --max-model-len 65536 \ --gpu-memory-utilization 0.92
python -m sglang.launch_server \ --model-path Tesslate/WEBGEN-4B-Preview \ --host 0.0.0.0 --port 5000 \ --mem-fraction-static 0.94 \ --attention-backend flashinfer \ --served-model-name webgen-4b
Inference Settings (suggested)
| Param | Value | Notes |
|---|---|---|
temperature | 0.6 | Balance creativity & consistency (lower if quantized) |
top_p | 0.9 | Nucleus sampling |
top_k | 40 | Optional vocab restriction |
max_new_tokens | 1200–2500 | Single-file sites often fit < 1500 |
repetition_penalty | 1.1 | Reduces repetitive classes/markup |
Prompts that work well
Starter
Make a single-file landing page for "RasterFlow" (GPU video pipeline). Style: modern tech, muted palette, Tailwind, rounded-xl, subtle gradients. Sections: navbar, hero (big headline + 2 CTAs), logos row, features (3x cards), code block (copyable), pricing (3 tiers), FAQ accordion, footer. Constraints: semantic HTML, no external JS. Return ONLY the HTML code.
Design-strict
Use an 8pt spacing system. Palette: slate with indigo accents. Typography scale: 14/16/18/24/36/56. Max width: 1200px. Avoid shadows > md; prefer borders/dividers.
Quantization & VRAM (example)
| Format | Footprint | Notes |
|---|---|---|
| BF16 | ~8–12 GB | Fastest, best fidelity |
| GGUF Q5_K_M | ~6–8 GB | Great quality/size trade-off |
| GGUF Q4_K_M | ~5–7 GB | Smallest comfortable for laptops |
## Intended Use & Scope
- Primary: Generate complete, single-file websites (landing pages, marketing pages, simple docs) with semantic HTML and Tailwind classes.
- Secondary: Component blocks (hero, pricing, FAQ) for manual composition.
Limitations
- Accessibility: adds headings/labels but ARIA coverage may need review.
- JS widgets: kept light unless explicitly requested in prompt.
Ethical Considerations
- Curate prompts appropriately.
- When using third-party logos/assets, ensure you have rights or use open sources.
Training Summary (research preview)
- Base:
Qwen/Qwen3-4B-Instruct - Objective: Tight web-only bias; reward semantic structure, spacing rhythm, and responsiveness.
- Data: Mixture of curated HTML/CSS/Tailwind snippets, component libraries, and synthetic page specs.
- Recipe: SFT with format constraints → instruction tuning → style/rhythm preference optimization.
- Context: effective ~64k; trained to keep default outputs within practical page length.
Example Outputs
Community
- Examples: uigenoutput.tesslate.com
- Discord: discord.gg/EcCpcTv93U
- Website: tesslate.com
“Why are good design models so expensive” — Tesslate Team
Citation
@misc{tesslate_webgen_4b_preview_2025,
title = {WEBGEN-4B-Preview: Design-first web generation with a 4B model},
author = {Tesslate Team},
year = {2025},
url = {https://huggingface.co/Tesslate/WEBGEN-4B-Preview}
}
- Downloads last month
- 388
Hardware compatibility
Log In to add your hardware
2-bit
3-bit
4-bit
5-bit
6-bit
8-bit
16-bit
Model tree for gabriellarson/WEBGEN-4B-Preview-GGUF
Base model
Qwen/Qwen3-4B-Instruct-2507 Finetuned
Tesslate/WEBGEN-4B-Preview