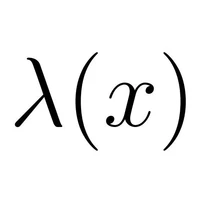Low Frame-rate Speech Codec: a Codec Designed for Fast High-quality Speech LLM Training and Inference
Large language models (LLMs) have significantly advanced audio processing through audio codecs that convert audio into discrete tokens, enabling the application of language modeling techniques to audio data. However, audio codecs often operate at high frame rates, resulting in slow training and inference, especially for autoregressive models. To address this challenge, we present the Low Frame-rate Speech Codec (LFSC): a neural audio codec that leverages finite scalar quantization and adversarial training with large speech language models to achieve high-quality audio compression with a 1.89 kbps bitrate and 21.5 frames per second. We demonstrate that our novel codec can make the inference of LLM-based text-to-speech models around three times faster while improving intelligibility and producing quality comparable to previous models.