
[Trimming] Granite 4.0
Collection
Collection of trimmed IBM's Granite 4.0 models. The models are sorted alphabetically. • 96 items • Updated
This model is a 7.10% smaller version of ibm-granite/granite-4.0-h-1b optimized for Spanish language via vocabulary size reduction using the trimming method.
This trimmed model should perform similarly to the original model with only 32,768 tokens and a much smaller memory footprint. However, it may not perform well for other languages as tokens not commonly used in the selected languages were removed from the vocabulary.
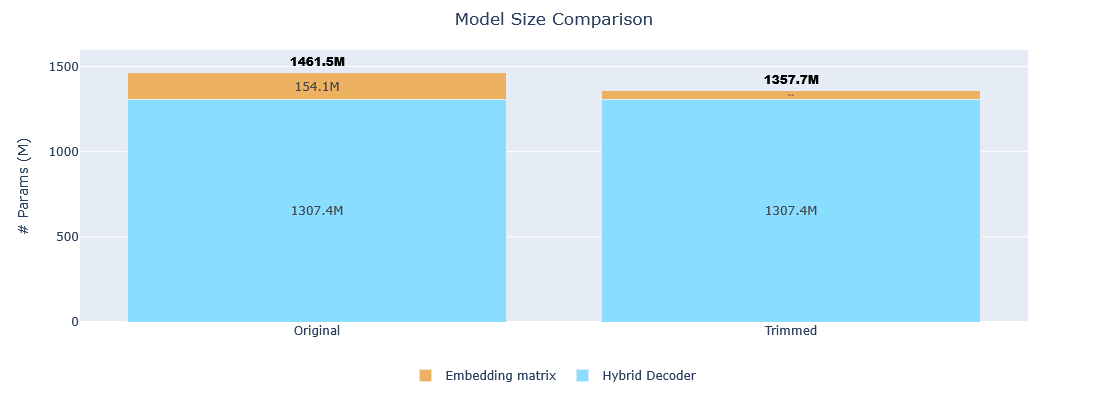
| Metric | Original | Trimmed | Reduction |
|---|---|---|---|
| Vocabulary size | 100,352 tokens | 32,768 tokens | 67.35% |
| Model size | 1,461,538,368 params | 1,357,729,344 params | 7.10% |
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
model_path = "alphaedge-ai/granite-4.0-h-1b-spa-32768"
tokenizer = AutoTokenizer.from_pretrained(model_path)
# drop device_map if running on CPU
model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device)
model.eval()
# change input text as desired
chat = [
{"role": "user", "content": "Your prompt in Spanish."},
]
chat = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# tokenize the text
input_tokens = tokenizer(chat, return_tensors="pt").to(device)
# generate output tokens
output = model.generate(**input_tokens, max_new_tokens=100)
# decode output tokens into text
output = tokenizer.batch_decode(output)
print(output[0])
@misc{granite2025,
author = {IBM Research},
title = {Granite 4.0 Language Models},
year = {2025},
howpublished = {https://github.com/ibm-granite/granite-4.0-language-models},
}
@misc{hf_blogpost_trimming,
title={Introduction to Trimming},
author={Loïck BOURDOIS and Tom AARSEN and Bram VANROY and Christopher AKIKI and Woojun JUNG and Manuel ROMERO and Prithiv SAKTHI},
year={2026},
url={https://huggingface.co/blog/lbourdois/introduction-to-trimming},
}
Base model
ibm-granite/granite-4.0-h-1b-base