
ORPO
Collection
This is the official collection of "ORPO: Monolithic Preference Optimization without Reference Model". • 5 items • Updated • 11
Mistral-ORPO is a fine-tuned version of mistralai/Mistral-7B-v0.1 using the odds ratio preference optimization (ORPO). With ORPO, the model directly learns the preference without the supervised fine-tuning warmup phase. Mistral-ORPO-⍺ is fine-tuned exclusively on HuggingFaceH4/ultrafeedback_binarized.
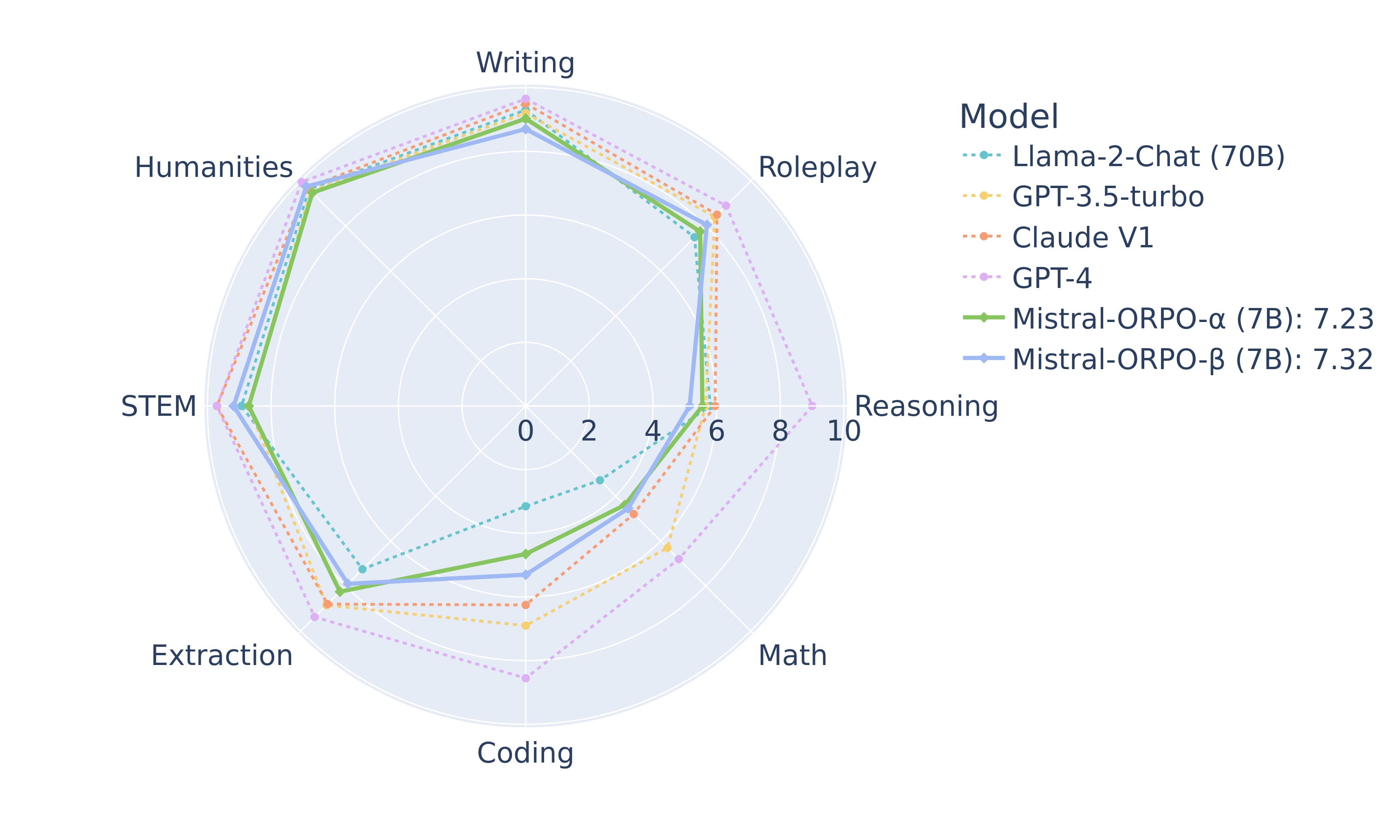
| Model Name | Size | Align | MT-Bench | AlpacaEval 1.0 | AlpacaEval 2.0 |
|---|---|---|---|---|---|
| Mistral-ORPO-⍺ | 7B | ORPO | 7.23 | 87.92 | 11.33 |
| Mistral-ORPO-β | 7B | ORPO | 7.32 | 91.41 | 12.20 |
| Zephyr β | 7B | DPO | 7.34 | 90.60 | 10.99 |
| TULU-2-DPO | 13B | DPO | 7.00 | 89.5 | 10.12 |
| Llama-2-Chat | 7B | RLHF | 6.27 | 71.37 | 4.96 |
| Llama-2-Chat | 13B | RLHF | 6.65 | 81.09 | 7.70 |
| Model Type | Prompt-Strict | Prompt-Loose | Inst-Strict | Inst-Loose |
|---|---|---|---|---|
| Mistral-ORPO-⍺ | 0.5009 | 0.5083 | 0.5995 | 0.6163 |
| Mistral-ORPO-β | 0.5287 | 0.5564 | 0.6355 | 0.6619 |
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("kaist-ai/mistral-orpo-alpha")
tokenizer = AutoTokenizer.from_pretrained("kaist-ai/mistral-orpo-alpha")
# Apply chat template
query = [{'role': 'user', 'content': 'Hi! How are you doing?'}]
prompt = tokenizer.apply_chat_template(query, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors='pt')
# Generation with specific configurations
output = model.generate(
**inputs,
max_new_tokens=128,
do_sample=True,
temperature=0.7
)
response = tokenizer.batch_decode(output)
#<|user|>
#Hi! How are you doing?</s>
#<|assistant|>
#I'm doing well, thank you! How are you?</s>
@misc{hong2024orpo,
title={ORPO: Monolithic Preference Optimization without Reference Model},
author={Jiwoo Hong and Noah Lee and James Thorne},
year={2024},
eprint={2403.07691},
archivePrefix={arXiv},
primaryClass={cs.CL}
}