
SVDQunat: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
Paper • 2411.05007 • Published • 24


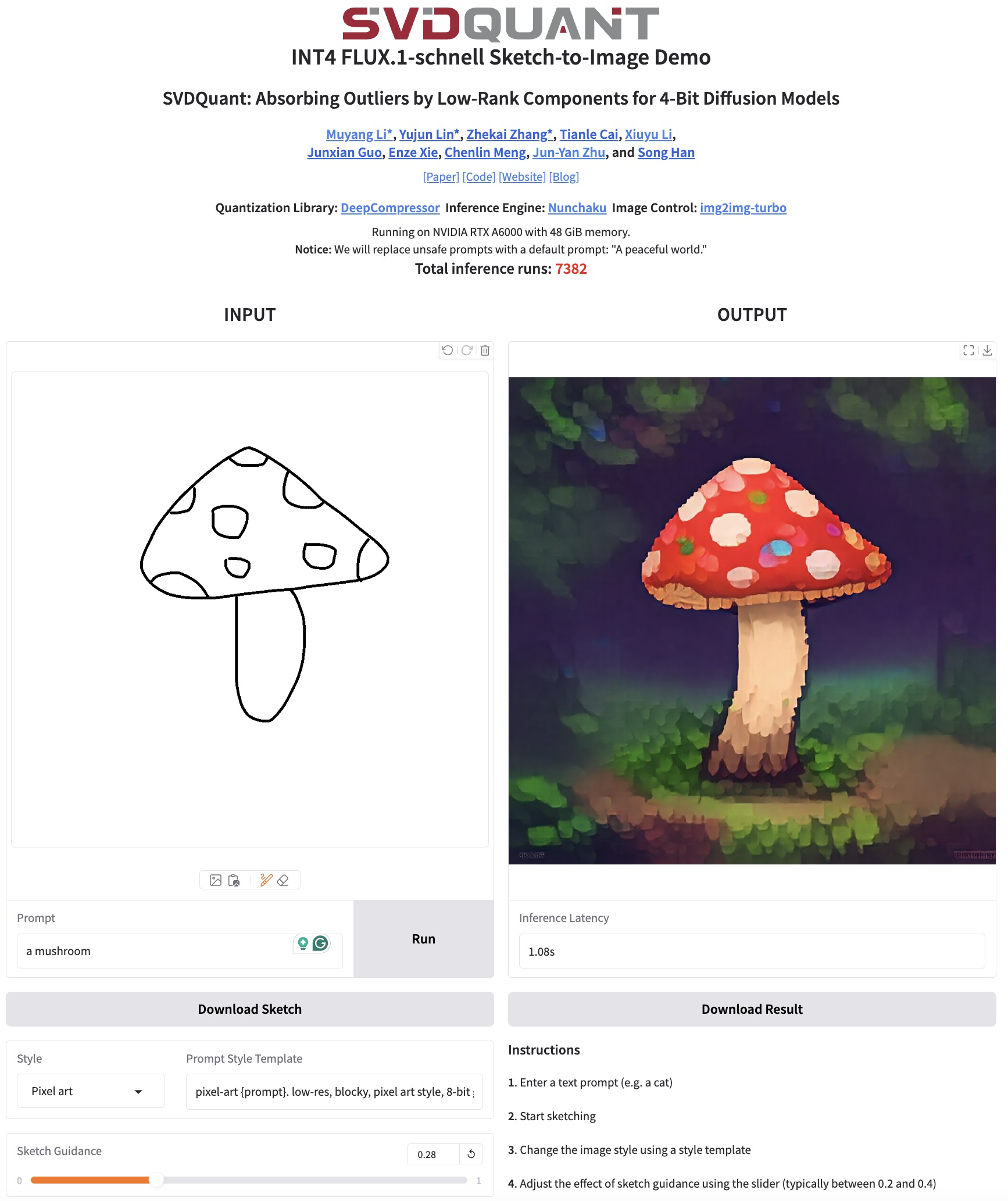 This repository contains img2img-turbo LoRAs for both original and Nunchaku-quantized FLUX.1-schnell to translate sketch to images from user prompts.
This repository contains img2img-turbo LoRAs for both original and Nunchaku-quantized FLUX.1-schnell to translate sketch to images from user prompts.
sketch.safetensors: Img2img sketch-to-image LoRA for original FLUX.1-schnell model.svdq-int4-sketch.safetensors: Img2img sketch-to-image LoRA for SVDQuant INT4 FLUX.1-schnell model.See https://github.com/nunchaku-tech/nunchaku/tree/main/app/flux.1/sketch.
@inproceedings{
li2024svdquant,
title={SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models},
author={Li*, Muyang and Lin*, Yujun and Zhang*, Zhekai and Cai, Tianle and Li, Xiuyu and Guo, Junxian and Xie, Enze and Meng, Chenlin and Zhu, Jun-Yan and Han, Song},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025}
}
@article{
parmar2024one,
title={One-step image translation with text-to-image models},
author={Parmar, Gaurav and Park, Taesung and Narasimhan, Srinivasa and Zhu, Jun-Yan},
journal={arXiv preprint arXiv:2403.12036},
year={2024}
}
Base model
black-forest-labs/FLUX.1-schnell