SliME
Collection
Traing data and models of SliME • 6 items • Updated • 6

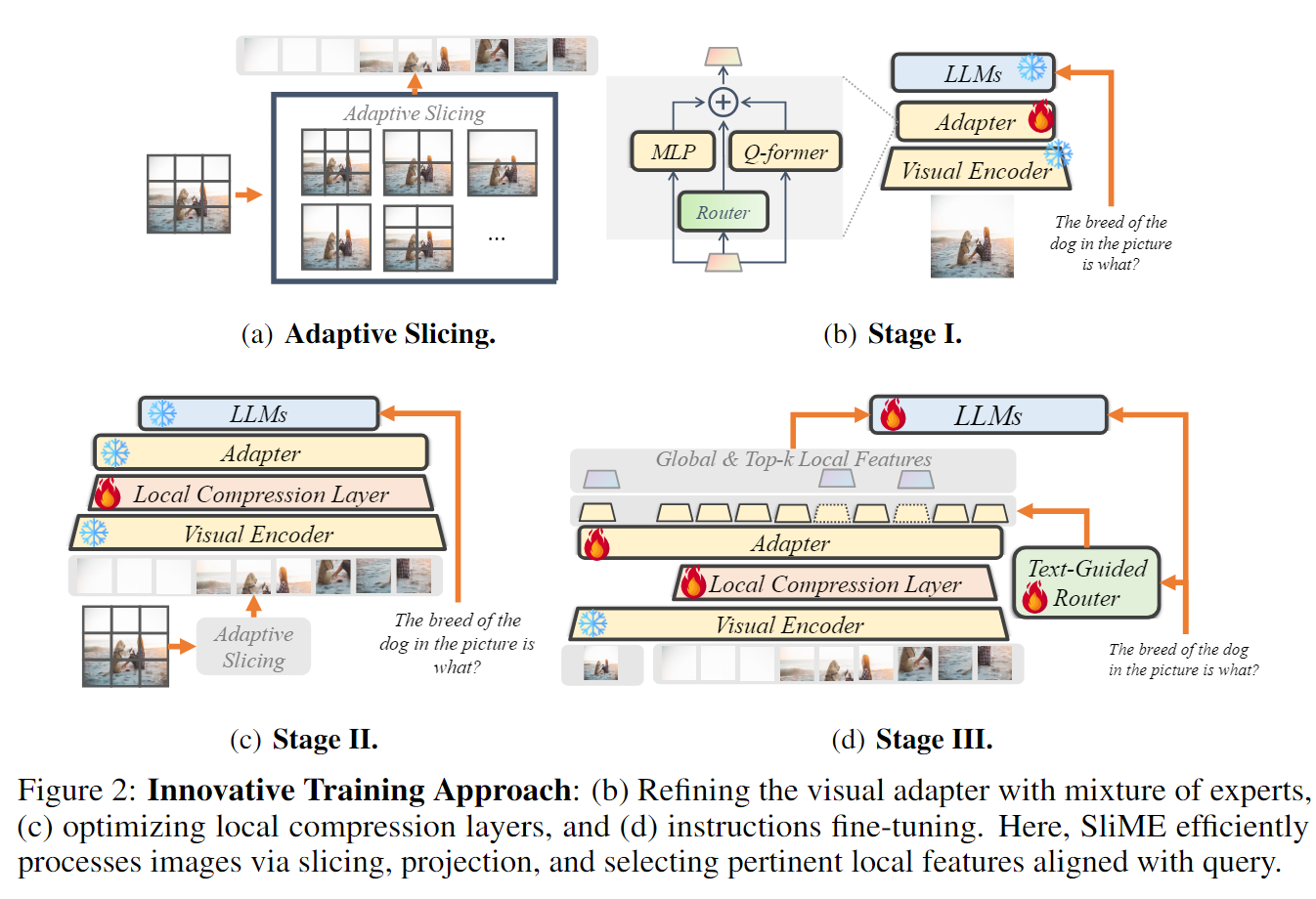
Model type: SliME is an open-source chatbot trained by fine-tuning LLM on multimodal instruction-following data. It is an auto-regressive language model, based on the transformer architecture. Base LLM: meta-llama/Meta-Llama-3-8B-Instruct
Paper or resources for more information:
Paper: https://huggingface.co/papers/2406.08487
Arxiv: https://arxiv.org/abs/2406.08487
Code: https://github.com/yfzhang114/SliME
Llama 3 is licensed under the LLAMA 3 Community License, Copyright (c) Meta Platforms, Inc. All Rights Reserved.
Where to send questions or comments about the model: https://github.com/yfzhang114/SliME/issues
Primary intended uses: The primary use of SliME is research on large multimodal models and chatbots.
Primary intended users: The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.
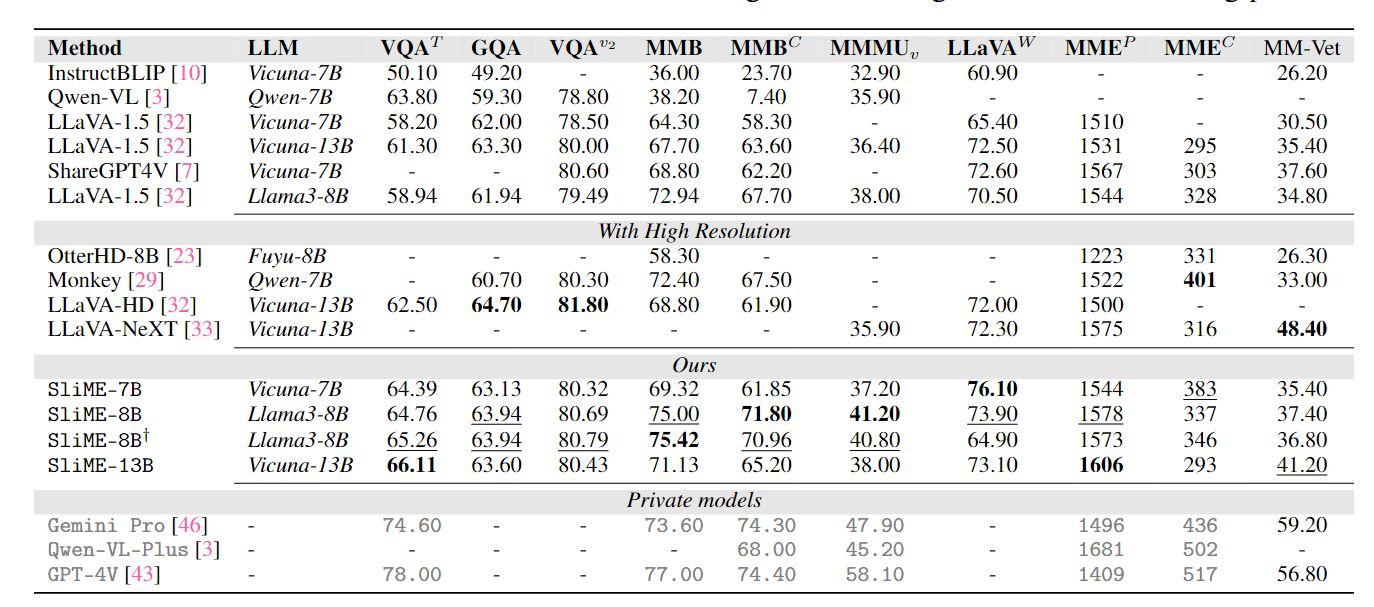
A collection of 15 benchmarks, including 5 academic VQA benchmarks and 10 recent benchmarks specifically proposed for instruction-following LMMs.